library(tidyverse)
library(openintro)
library(infer)
library(knitr)
library(ggpubr)
library(kableExtra)
library(gghighlight)
library(scales) # label_dollar
options(pillar.print_min = 9) # to avoid annoying scroll behavior
knitr::opts_chunk$set(out.height = "100%")
theme_set(theme_bw() + theme(axis.text = element_text(size = 14),
axis.title = element_text(size = 16),
))Inference for comparing many means
STA35B: Statistical Data Science 2
Consider the following toy ANOVA Data
Does it look like the diffrnces in group means could come from random chance?
- Compare I vs II vs III, then compare IV vs V vs VI
- group I has same center as group IV;
group II has same center as group V;
group III has same center as group VI.
- group I has same center as group IV;
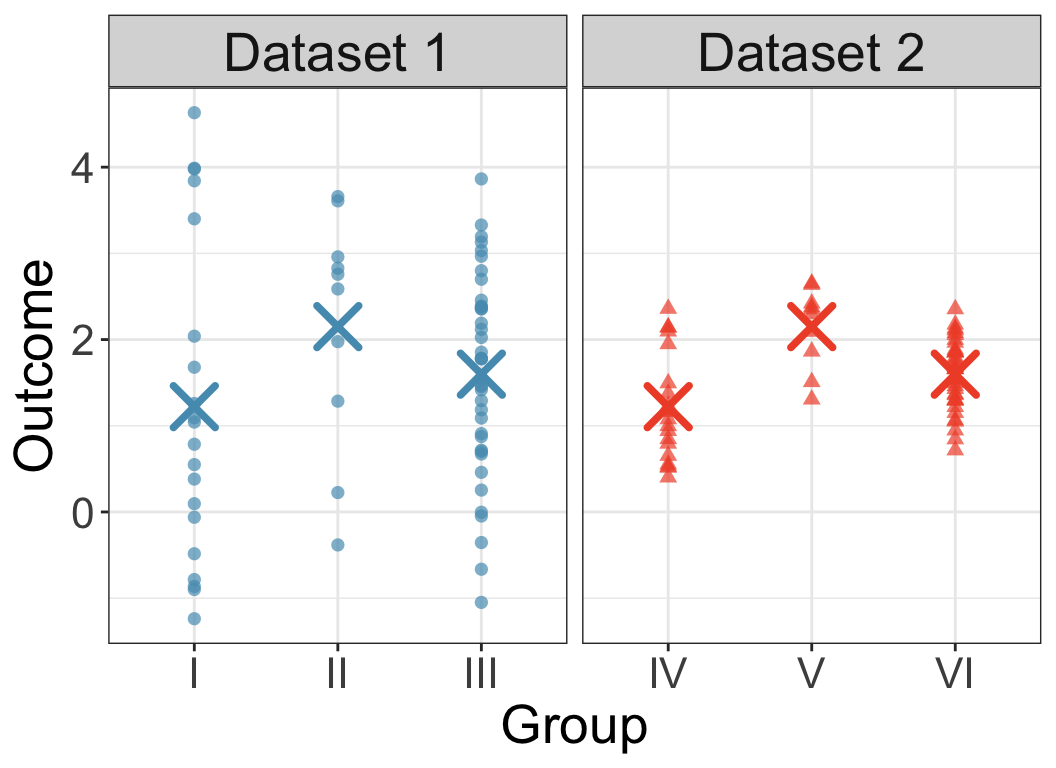
Consider the ratio \[\frac{\text{between-group variability}}{\text{within-group variability}}\]
- What does this look like for Groups I/II/III? For groups IV/V/VI?
- What does a large ratio value suggest?
What does a small ratio value suggest?
(see next slide)
F statistic
Goal: assess whether the observed variability in sample group means is due to random chance.
- For between-group variability, consider the sum of squares between groups (SSG): \[SSG = \sum_{j=1}^k n_j (\bar x_j - \bar x)^2\]
- \(k\) is the number of means we are comparing;
- \(n_j\) is the number of observations in group \(j\);
- \(\bar x_j\) is the sample mean of group \(j\);
- \(\bar x\) is the overall sample mean across all observations.
- For within-group variability, consider the sum of squares errors (SSE): \[\begin{align*}SSE&= \sum_{j=1}^k \sum_{i=1}^{n_j} ( x_{j,i} - \bar x_j)^2\end{align*}\]
SSG: variability of group means (weighted by group size)
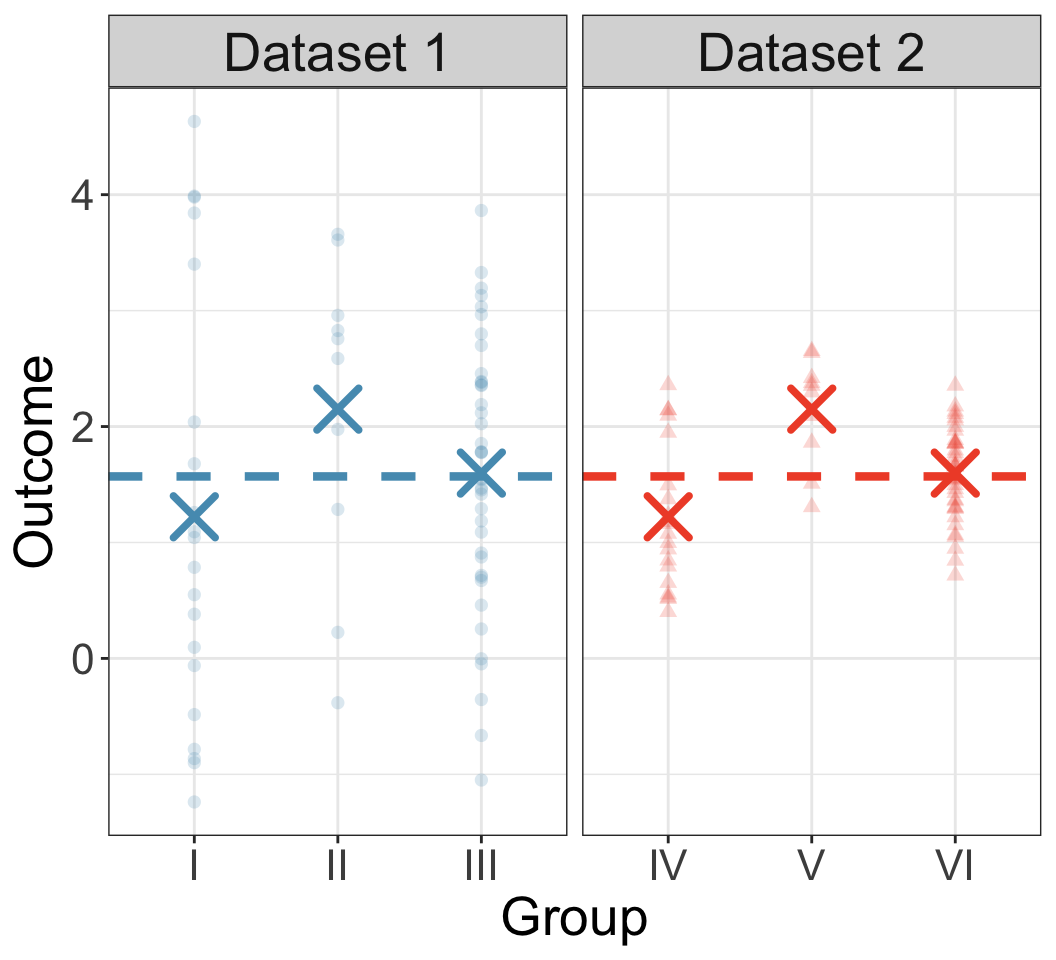
SSE: variability within each group
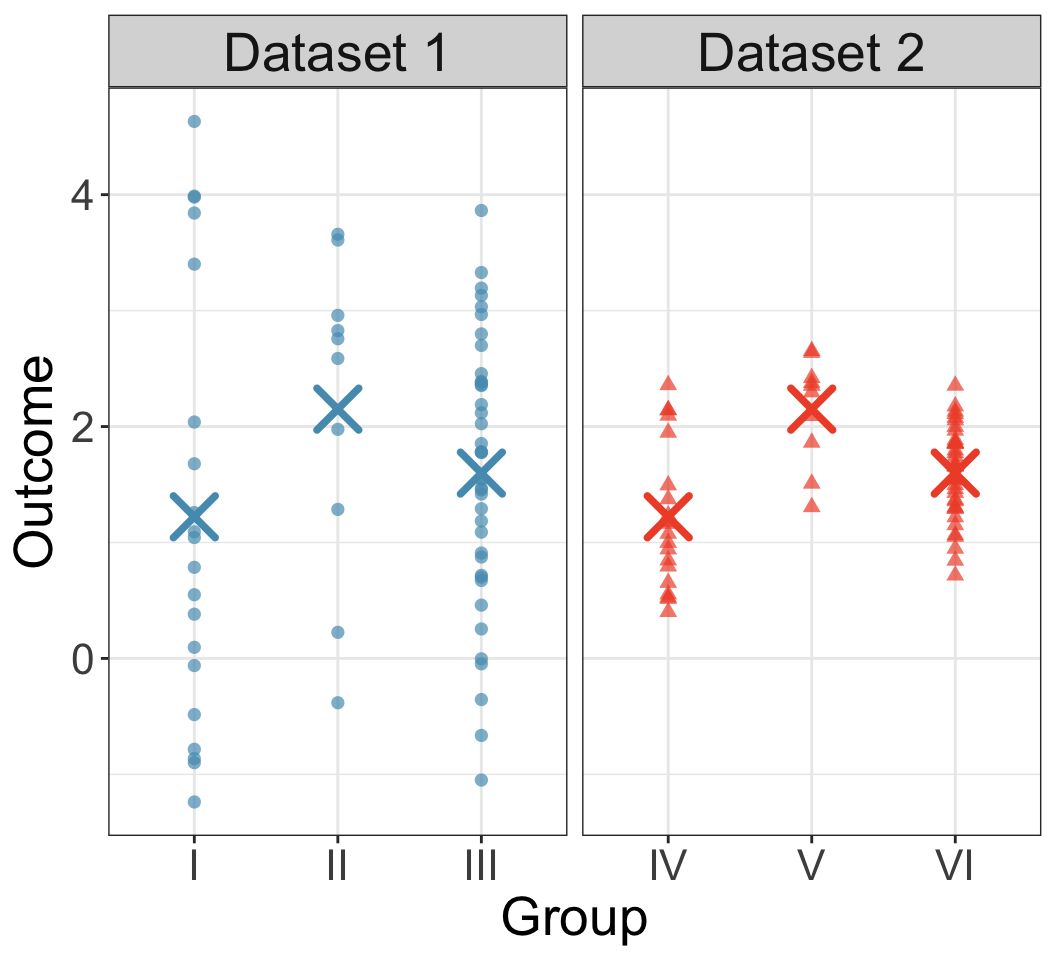
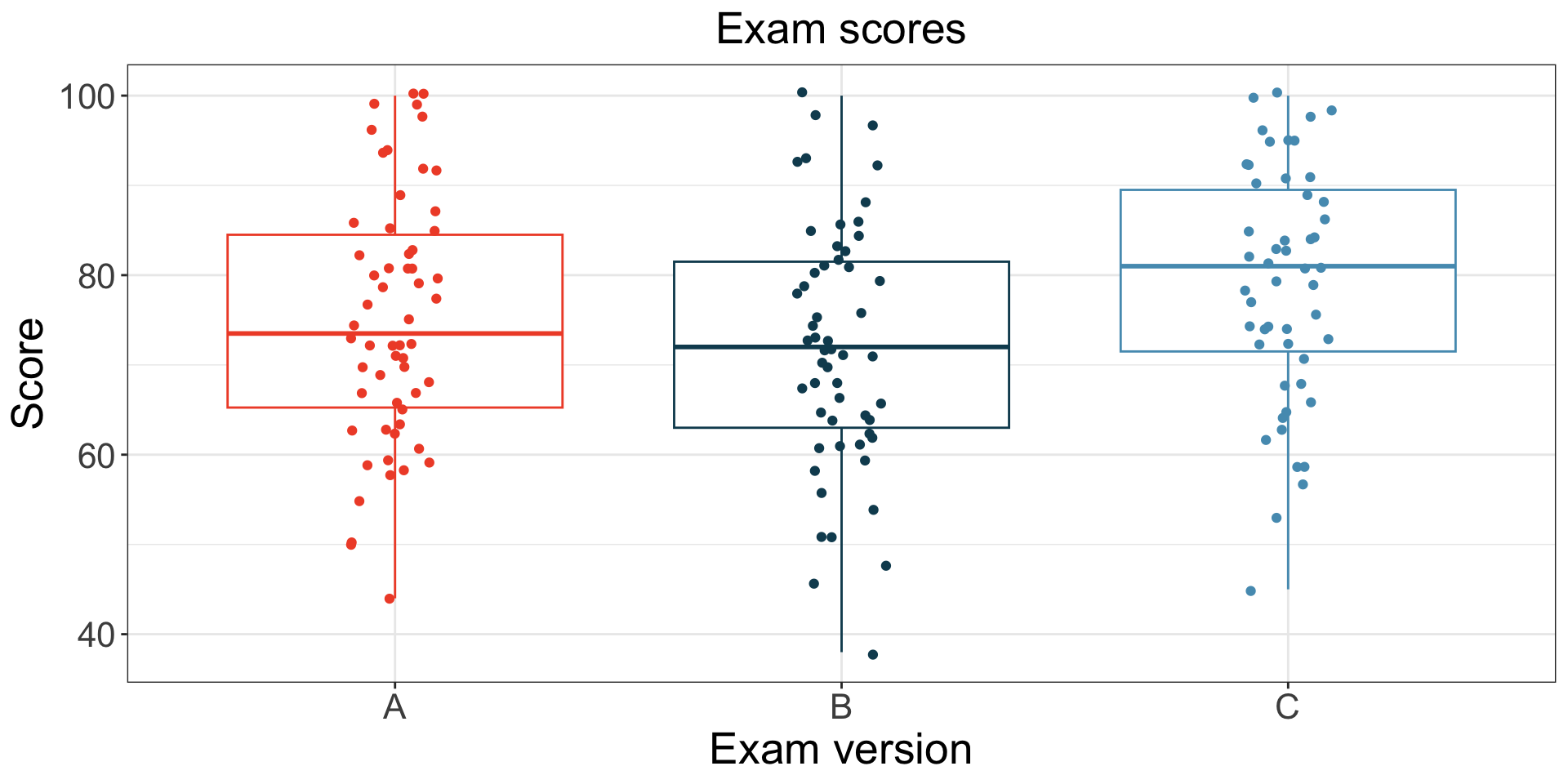
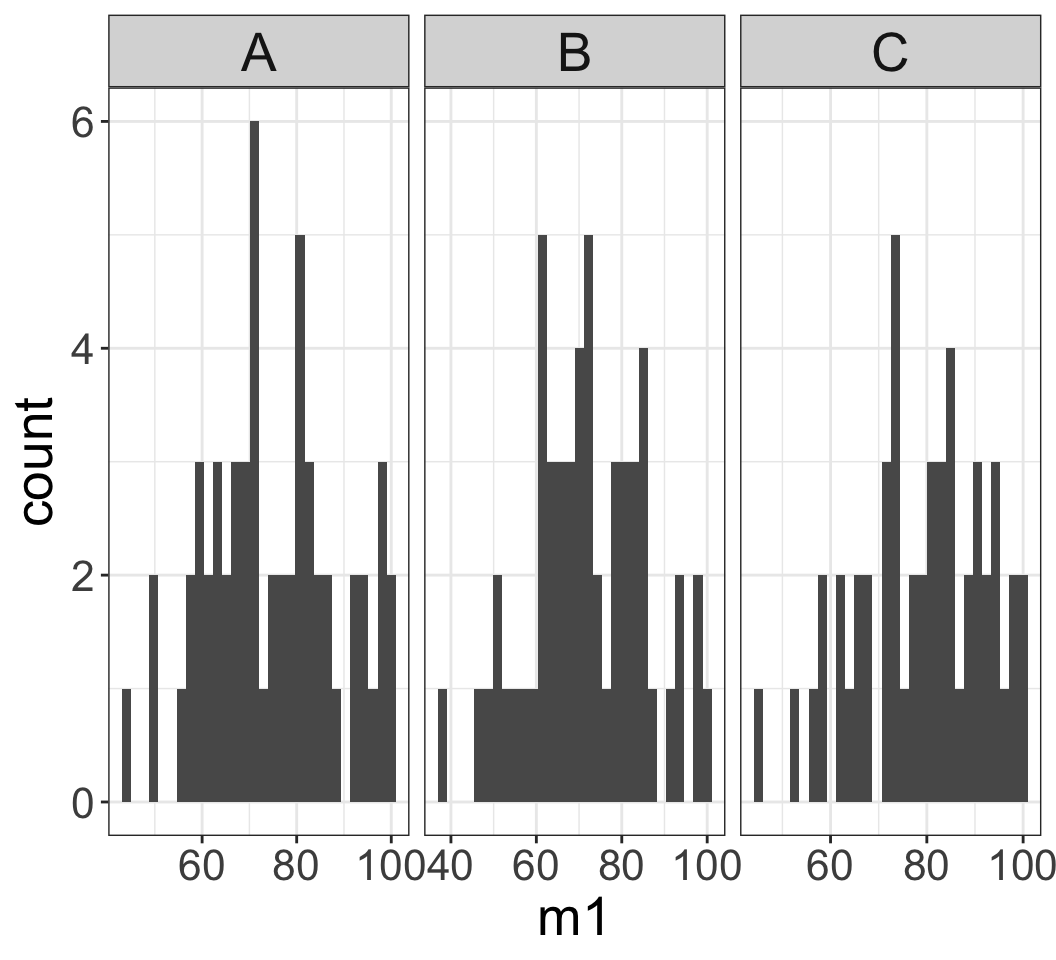
Example: class exam
A teacher gave three versions (A, B, C) of an exam.
- Data is summarized in table/plot to the right.
- Is the exam difficulty the same across the three versions?
Hypothesis test:
- \(H_0\): All three versions are equally difficult. \[\mu_A = \mu_B = \mu_C\]
- \(H_A\): At least one version is inherently more (or less) difficult than the others.
| Version | n | Mean | SD | Min | Max |
|---|---|---|---|---|---|
| A | 58 | 75.1 | 13.9 | 44 | 100 |
| B | 55 | 72.0 | 13.8 | 38 | 100 |
| C | 51 | 78.9 | 13.1 | 45 | 100 |
Class Data Randomization Test
Randomization test with many means: same idea as in two means.
- Null assumption: versions are equally difficult.
- Exam version (A or B or C) is randomly allocated to the exam scores, under the null assumption.
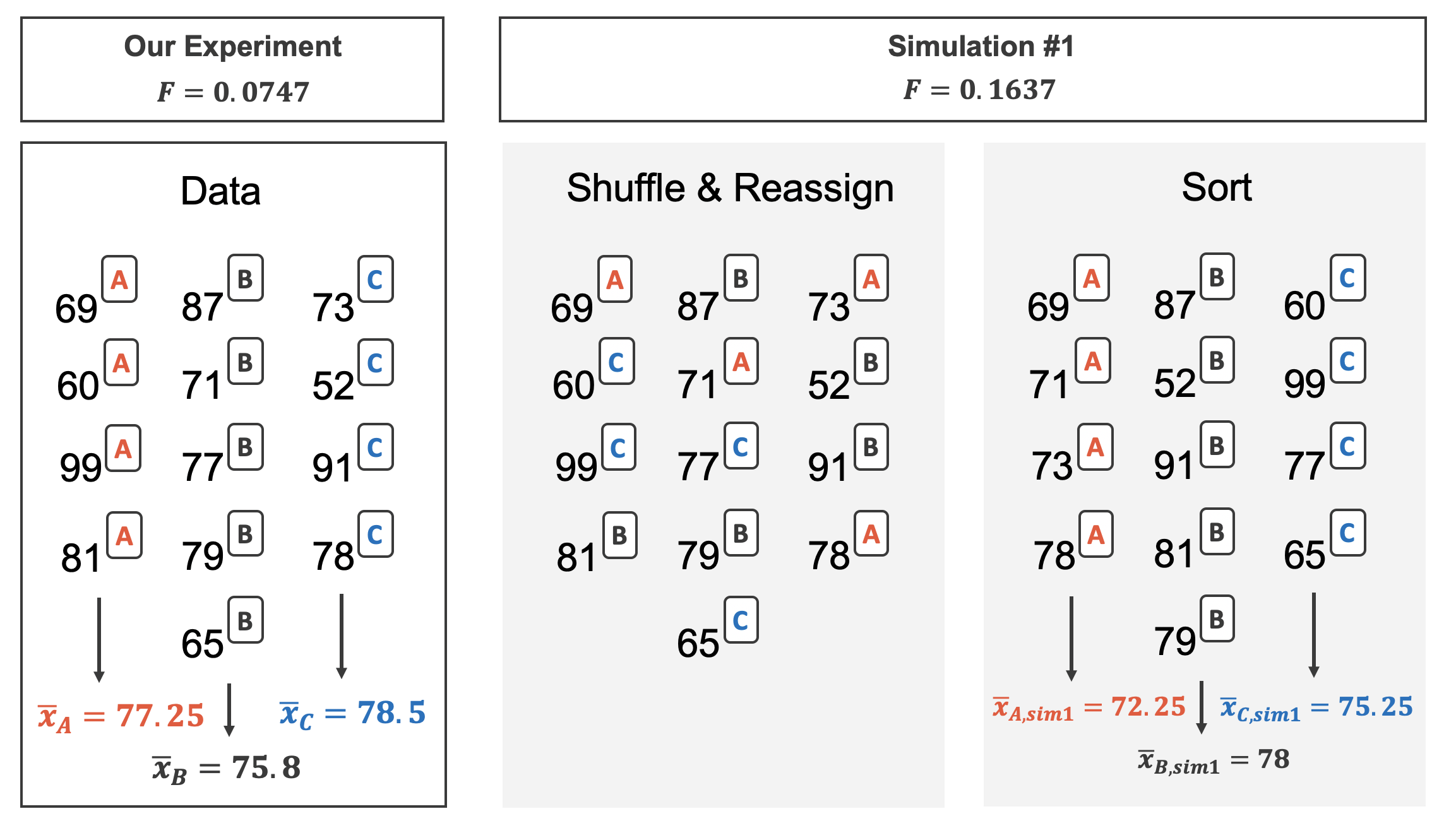
- For each simulation, we calculate the F statistic.
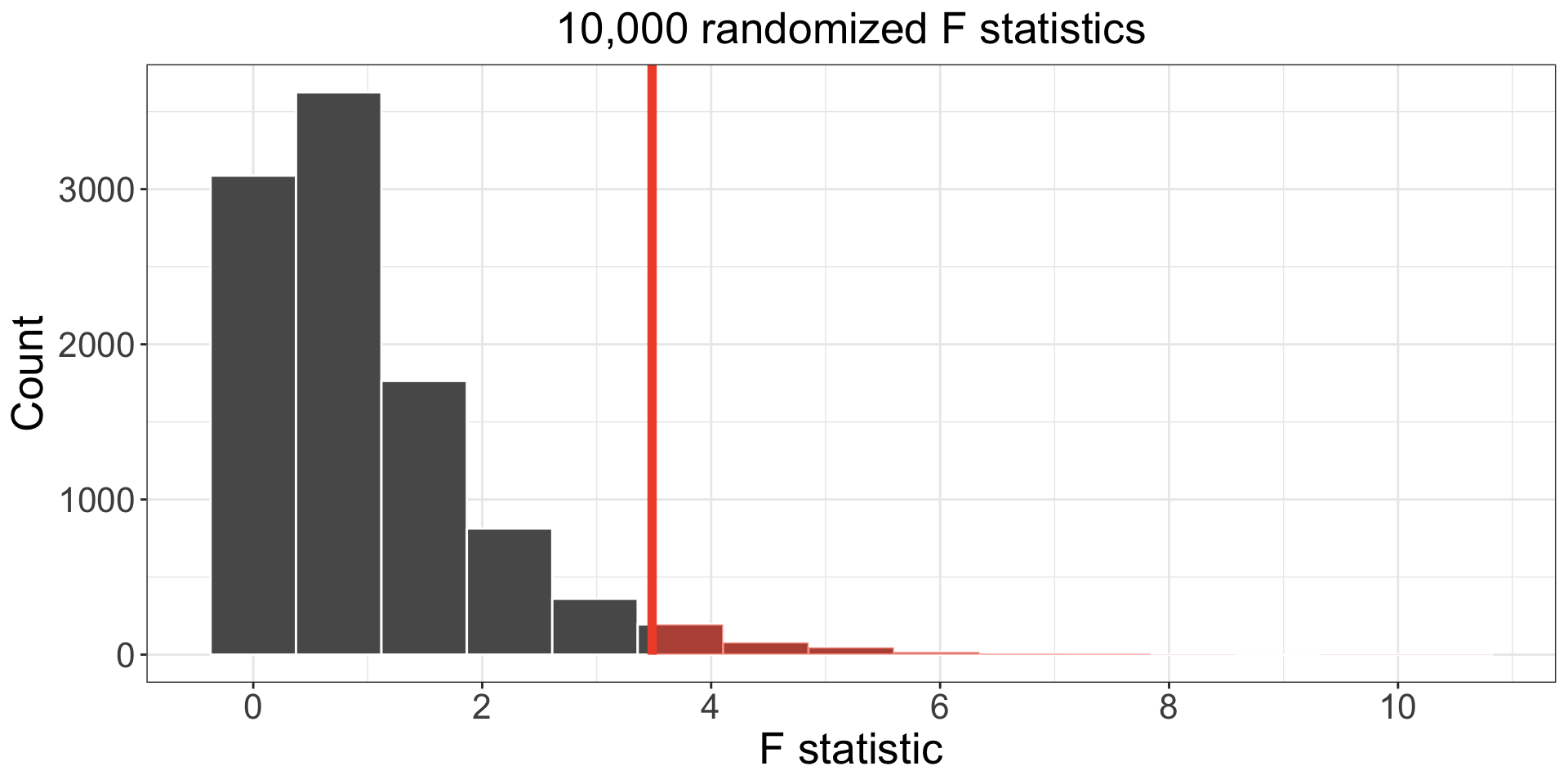
- 297 of 10,000 simulations had an F statistic greater than or equal to the observed value 3.48.
- p-value 0.0297 is below 0.05, so we reject \(H_0\).
- Conclusion: our observed value is unlikely due to chance if all exams were equally difficult.
Test statistic for three or more means is an F statistic
Recall: the F statistic is a ratio of how the groups differ (MSG) as compared to how the observations within a group vary (MSE).
\[F = \frac{MSG}{MSE}\]
- When the \(H_0\) is true and the conditions below are met, the F statistic follows an F distribution with parameters \(df_1 = k-1\) and \(df_2 = n-k.\)
Conditions:
- the observations are independent within and between groups,
- the responses within each group are nearly normal, and
- the variability across the groups is about equal.
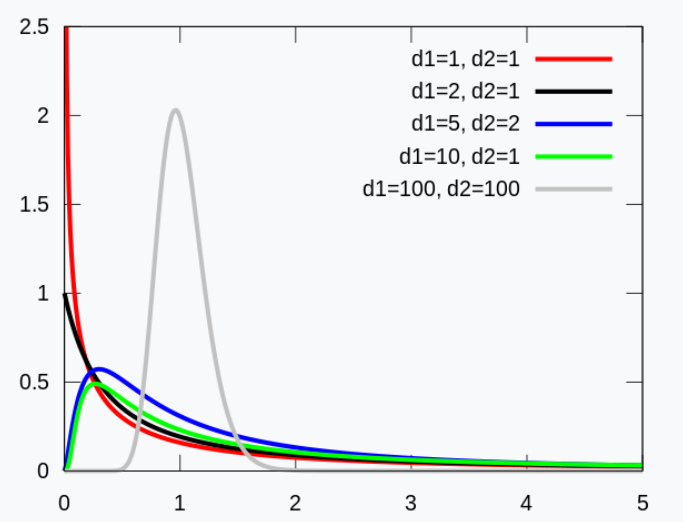
F distribution
- is determined by two parameters, \(df_1\) and \(df_2\), representing deg of freedom
- is always non-negative, so it does NOT look like t or normal distribution
ANOVA with lm and anova
Alternatively, we can perform analysis of variance using lm() and anova():
(lm_class <- lm(m1 ~ exam, data = classdata))
Call:
lm(formula = m1 ~ exam, data = classdata)
Coefficients:
(Intercept) examB examC
75.103 -3.140 3.838 anova(lm_class) |> broom::tidy() |> kable(digits=c(0, 0, 0, 0, 3, 3))| term | df | sumsq | meansq | statistic | p.value |
|---|---|---|---|---|---|
| exam | 2 | 1290 | 645 | 3.484 | 0.033 |
| Residuals | 161 | 29810 | 185 | NA | NA |
df: degrees of freedom \(df_1=k-1\) and \(df_2=n-k\)sumsq: SSG (top) and SSE (bottom)meansq: MSG (top) and MSE (bottom)statistic: F statistic: \(F = \frac{MSG}{MSE}\)p.value: p-value for the F statistic
Is this p-value valid? Need to check conditions:
- Independence: if data comes from simple random sample, this holds. For students we aren’t sure, so this might present problems, but let’s assume it’s OK
- Approximate normality - when sample size is large and no extreme outliers, then this is ok
- Approximately constant variance - each group has approximately the same variance
- Thus, we can use to reject \(H_0\) under 0.05 discernibiliity level.
Example: Batting in MLB
Does batting performance of baseball players differs according to position?
- Outfielder (OF)
- Infielder (OF)
- Catcher (C)
Data: 429 Major League Baseball (MLB) players from 2018, each \(\geq 100\) at bats.
Does the on-base percentage (OBP) differ across these 3 groups?
Some variables and descriptions:
# A tibble: 4 × 2
variable col1
<chr> <chr>
1 name Player name
2 team abbreviated name of the player's team
3 position player's primary field position (OF, IF, C)
4 OBP On-base percentage - First few rows:
| name | team | position | OBP |
|---|---|---|---|
| Abreu, J | CWS | IF | 0.325 |
| Acuna Jr., R | ATL | OF | 0.366 |
| Adames, W | TB | IF | 0.348 |
| Adams, M | STL | IF | 0.309 |
positionhas three levels:
unique(mlb_players_18$position)[1] OF IF C
Levels: OF IF CNull and alternative hypotheses:
- \(H_0\): the OBP for these three positions is the same; \[\mu_{OF} = \mu_{IF} = \mu_C\]
- \(H_A\): there is some difference among these three groups: \[\mu_{OF} \neq \mu_{IF}, \quad \mu_{IF} \neq \mu_C, \quad\text{or}\quad \mu_{OF} \neq \mu_C\]
ANOVA analysis
First, we need to check the conditions for F statistic / ANOVA analysis to hold.
- Independence: if data comes from simple random sample, this holds. For MLB we aren’t sure, so this might present problems, but let’s assume it’s OK
- Approximate normality - when sample size is large and no extreme outliers, then this is ok
- Approximately constant variance - variance within each group is approximately the same across groups
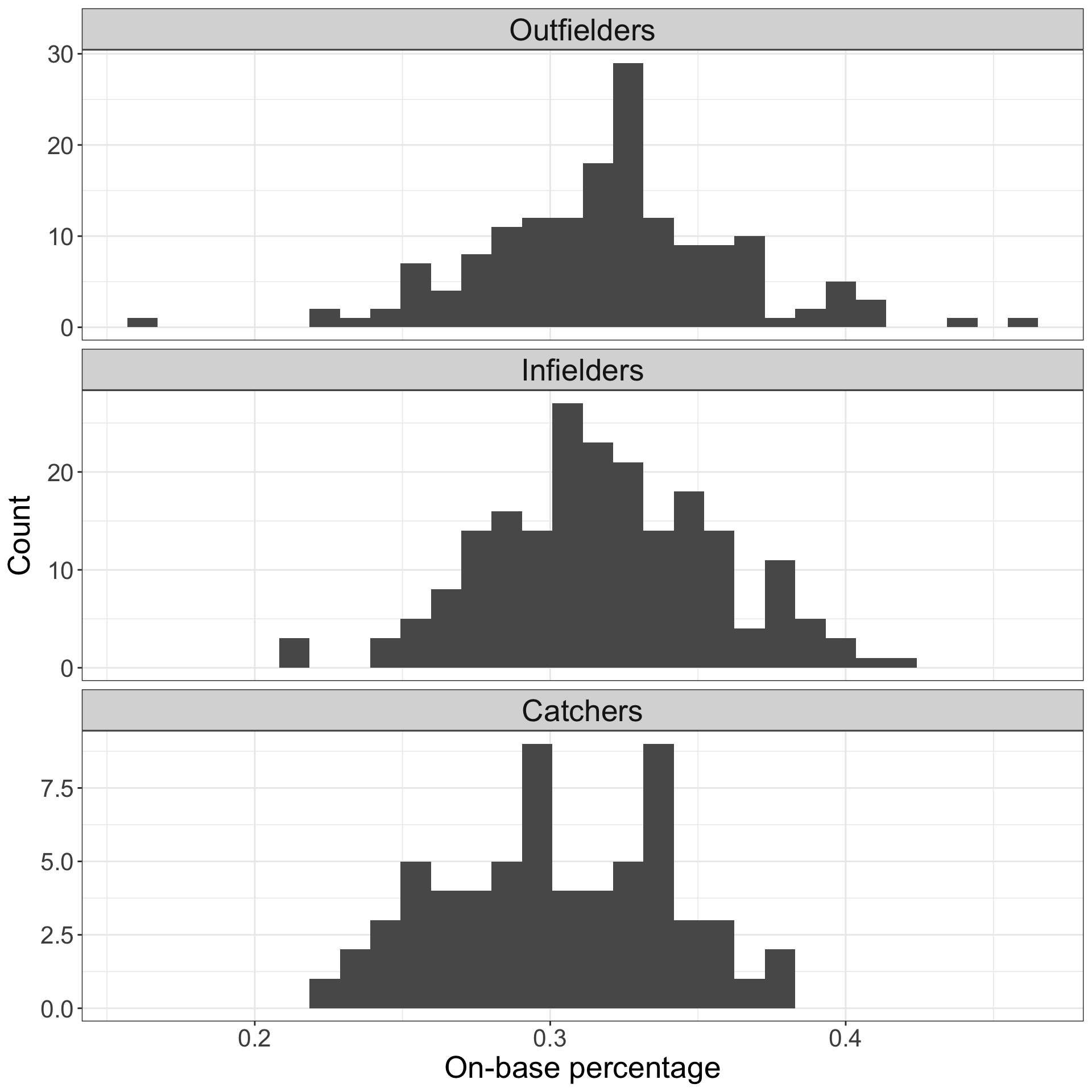
- Does appear to be approximately normal, no extreme outliers
- We see that variability across the groups is quite similar
- So our F statistic analysis can proceed
MLB ANOVA Output
To do analysis of variance, we use lm() and anova():
(mod <- lm(OBP~position, data=mlb_players_18))
Call:
lm(formula = OBP ~ position, data = mlb_players_18)
Coefficients:
(Intercept) positionIF positionC
0.319819 -0.001433 -0.017881 anova(mod) |>
broom::tidy() |>
kable(digits=c(0,0,3,4,2,3))| term | df | sumsq | meansq | statistic | p.value |
|---|---|---|---|---|---|
| position | 2 | 0.016 | 0.0080 | 5.08 | 0.007 |
| Residuals | 426 | 0.674 | 0.0016 | NA | NA |
How to read ANOVA output table?
df: degrees of freedom \(df_1=k-1\) and \(df_2=n-k\)sumsq: SSG (top) and SSE (bottom)meansq: MSG (top) and MSE (bottom)statistic: F statistic: \(F = \frac{MSG}{MSE}\)p.value: p-value for the F statistic- p-value is smaller than 0.05, so we can reject the null hypothesis
Can derive this entire tibble by using just df and sumsq (and pf() to calc p-value from the statistic)
meansq:sumsqdivided bydfstatistic: quotient of the twomeansqvalues- For
p.value, can usepf:
1 - pf(5.077, df1 = 2, df2 = 426)[1] 0.006621471