library(tidyverse)
library(openintro)
library(infer)
library(knitr)
library(ggpubr)
library(kableExtra)
library(gghighlight)
library(scales) # label_dollar
options(pillar.print_min = 9) # to avoid annoying scroll behavior
knitr::opts_chunk$set(out.height = "100%")
theme_set(theme_bw() + theme(axis.text = element_text(size = 14),
axis.title = element_text(size = 16),
))Inference for Comparing Paired Means
STA35B: Statistical Data Science 2
Randomization Test for Pairs
Let’s examine this procedure in the context of the following study.
Tire Tread Study
Research question: After 1,000 miles of driving, do Smooth Turn and Quick Spin tires have different average tread remaining?
Design:
- 25 cars
- each car gets one tire of each brand
- tread is measured after 1,000 miles
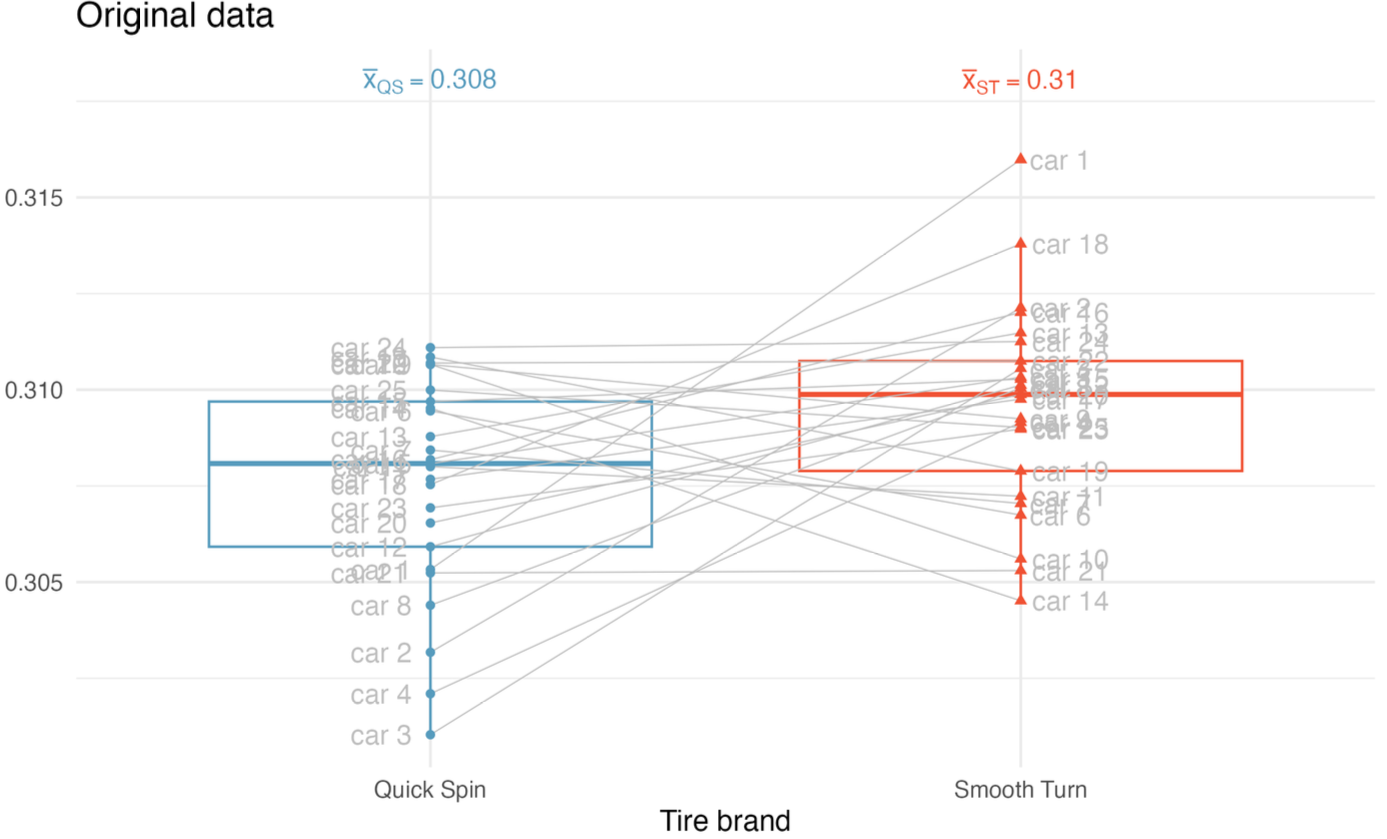
Observed means:
\[ \bar{x}_{Smooth} = 0.310,\quad \bar{x}_{Quick} = 0.308 \]
Define:
\[ d_i = \text{Smooth Turn tread}_i - \text{Quick Spin tread}_i \]
Then:
\[ \bar{d} = 0.310 - 0.308 = 0.002 \]
Hypotheses:
\[ H_0: \mu_d = 0 \qquad H_A: \mu_d \ne 0 \]
Randomization Test for Pairs
Under \(H_0\), tire brand should not matter within a car. So, for each car:
- keep the two tread measurements together (the pair structure stays intact!),
- randomly decide whether to keep or swap the brand labels,
- compute the mean paired difference,
- repeat many times.
What Changes?
- Independent two-sample randomization: shuffle group labels across all observations.
- Paired randomization: swap labels within each pair.
Tire Study: Conclusion
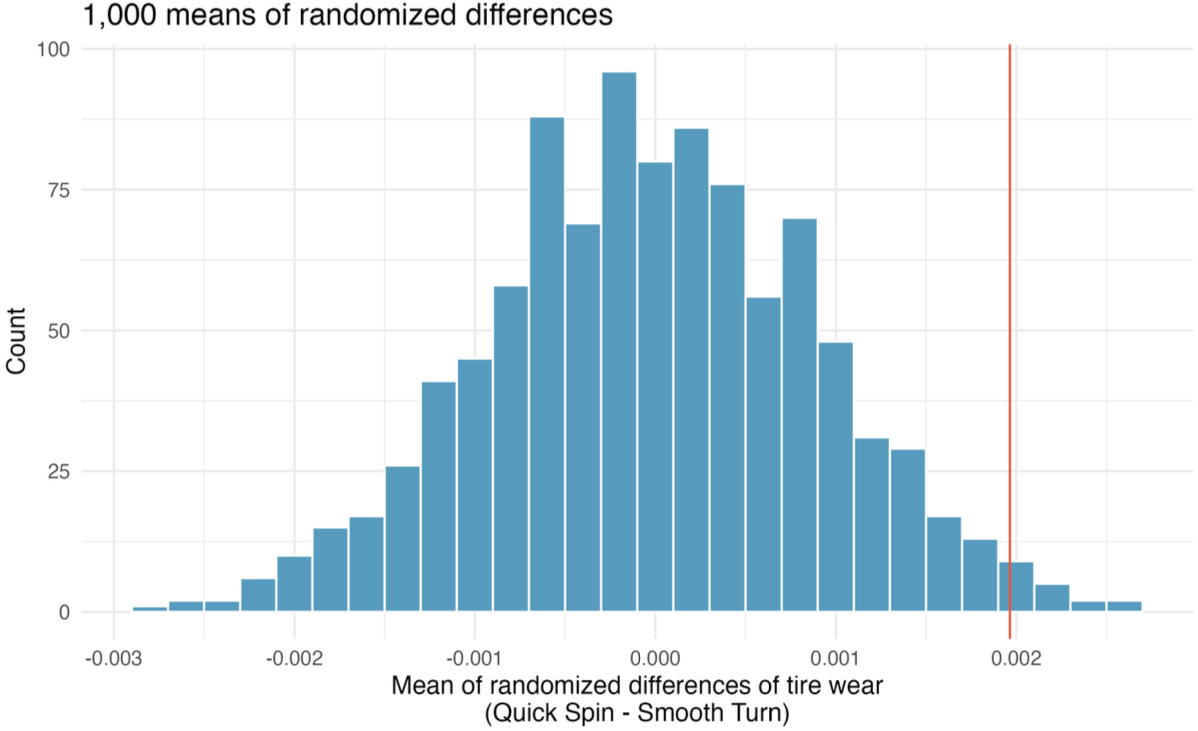
- Randomization distribution is centered near 0 because it is generated under \(H_0\).
- The observed mean difference, \(\bar{d} = 0.002\), falls far from the typical randomized differences.
Conclusion: the data provide evidence of a difference in average tread remaining.