Proportion of treatment patients who survive: \(\hat p_T = \frac{14}{40} = 0.35\)
Proportion of control patients who survive: \(\hat p_C = \frac{11}{50} = 0.22\)
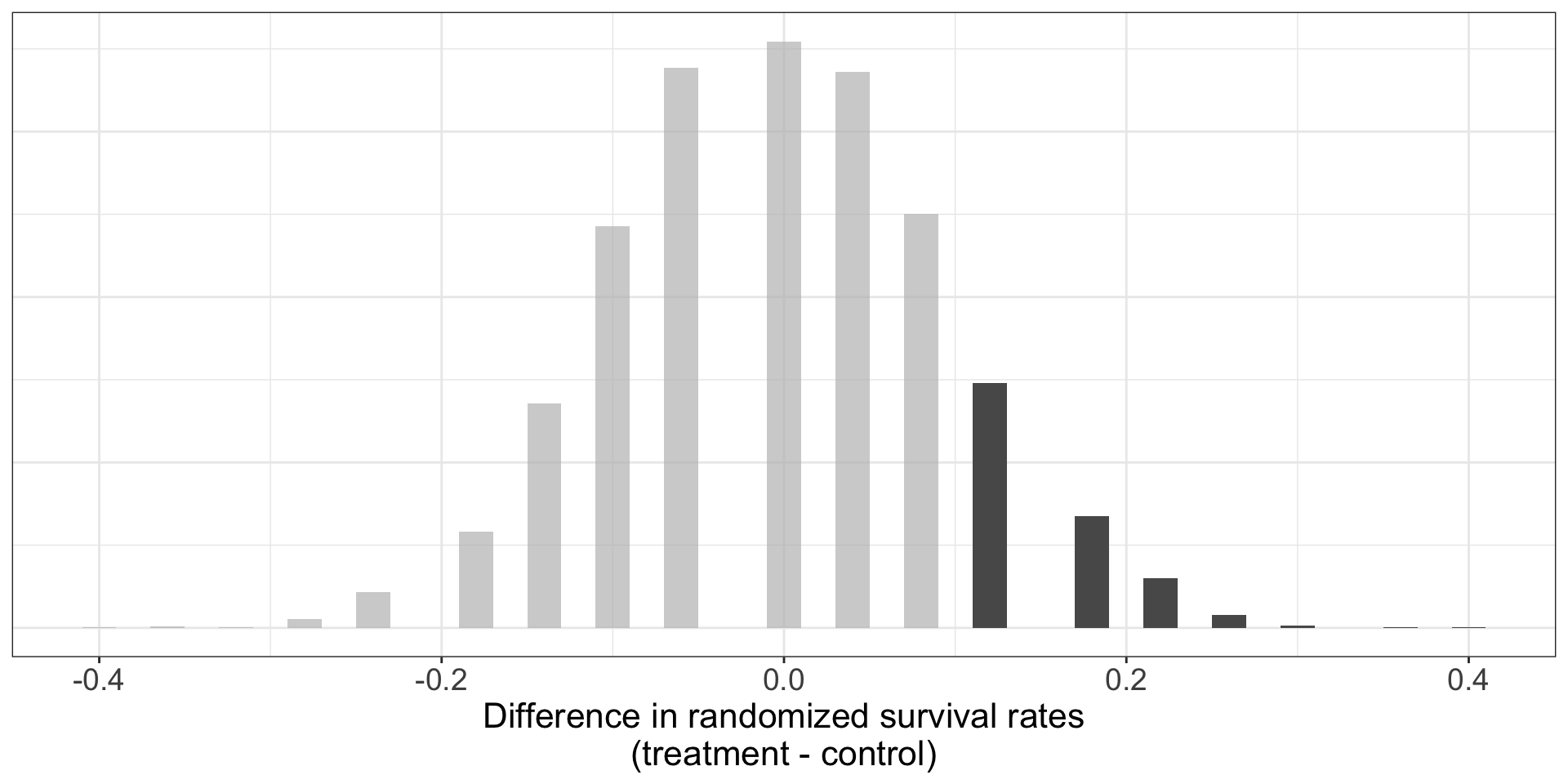
How likely would observed \(\hat p_T - \hat p_C = 0.13\) occur due to random chance?
Randomization test
Formulate a hypothesis test:
\(H_0\): blood thinners after CPR is independent of survival: \(p_1-p_2=0\).
\(H_A\): blood thinners after CPR increase chance of survival: \(p_1-p_2>0\).
Since initial assignment of treatment/control was random, if we reject the null, we can say that difference was due to usage of blood thinners (causal claim).
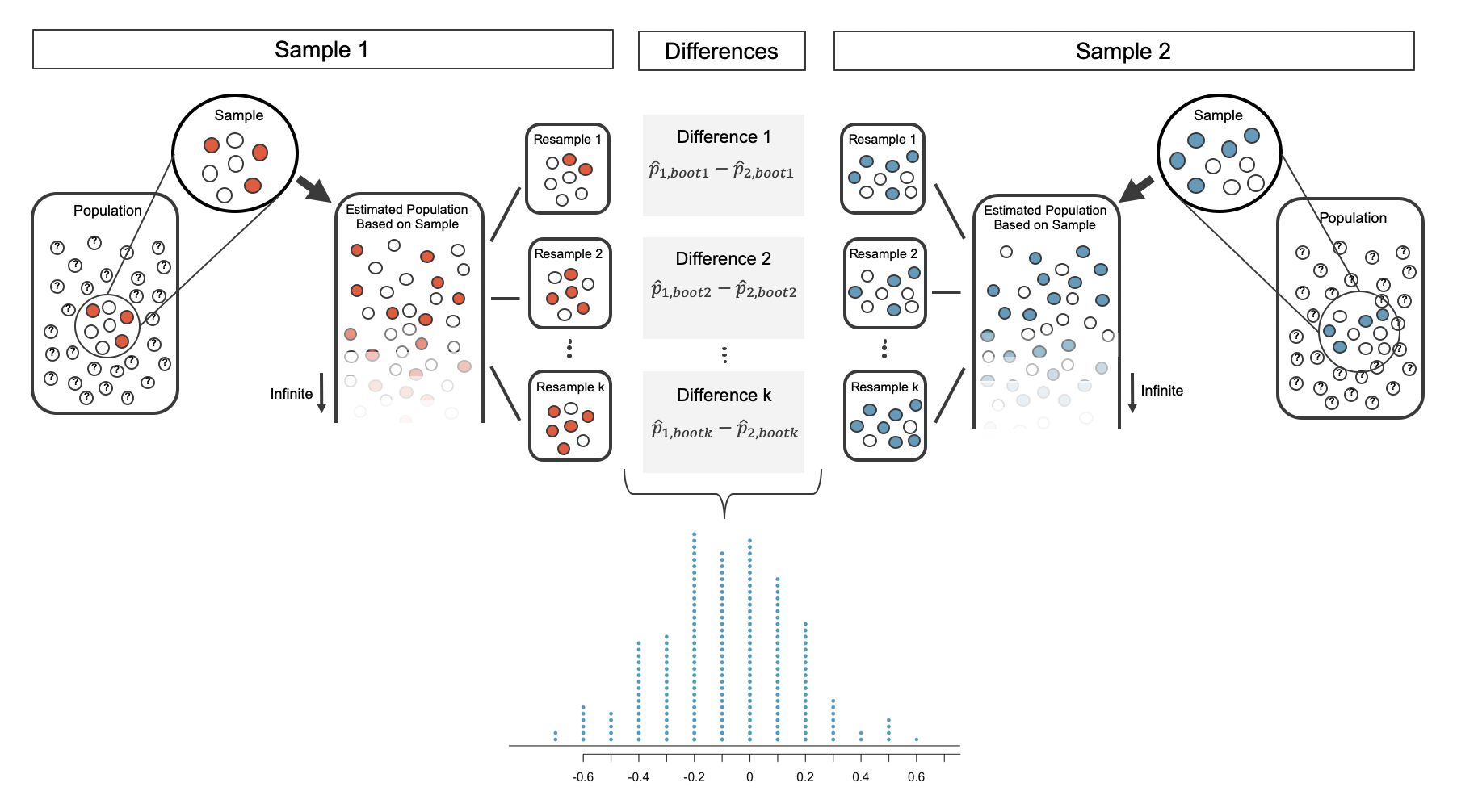
Randomization procedure
Assume that the same number of people died (65) / survived (25).
Then see what happens if we randomly assign treatment or control to each.
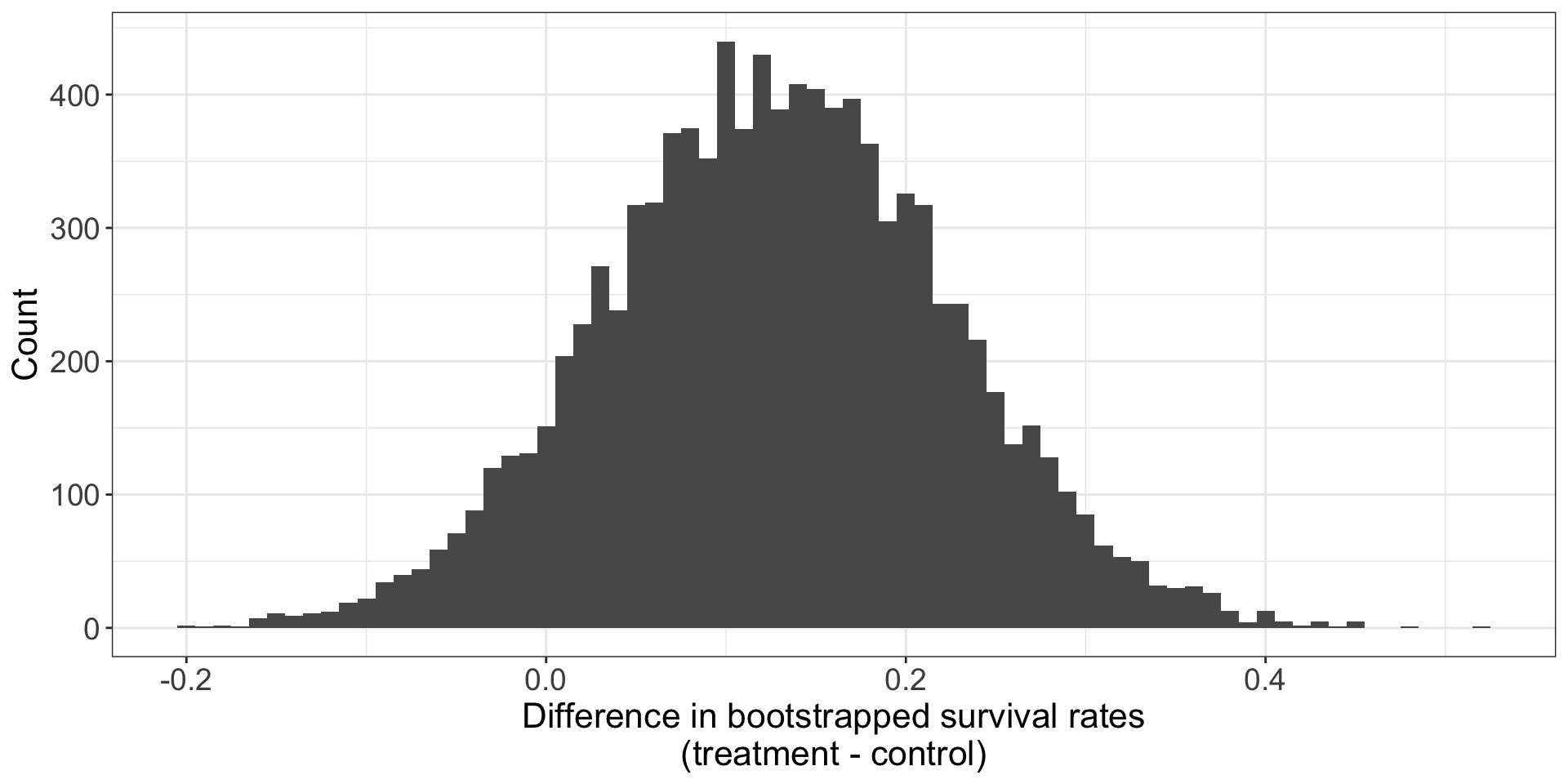
95% confidence that in the population, the true difference in survival rate for people receiving blood thinners post CPR is between 0.059 lower and 0.318 higher than the survival rate for non-receivers.
Similar calculation for 90% CI (which will be a narrower interval):
Like with \(\hat p\) for a single proportion, the difference \(\hat p_1 - \hat p_2\) can be modeled with a normal distribution under certain (more stringent) assumptions:
Independence: data within each group and between groups are independent; generally satisfied if in randomized experiment.
Success-failure: at least 10 successes and 10 failures within each group.
When these conditions are satisfied, the standard error of \(\hat p_1 - \hat p_2\) is
\(\hat{p}_1\) and \(\hat{p}_2\) represent the observed sample proportions.
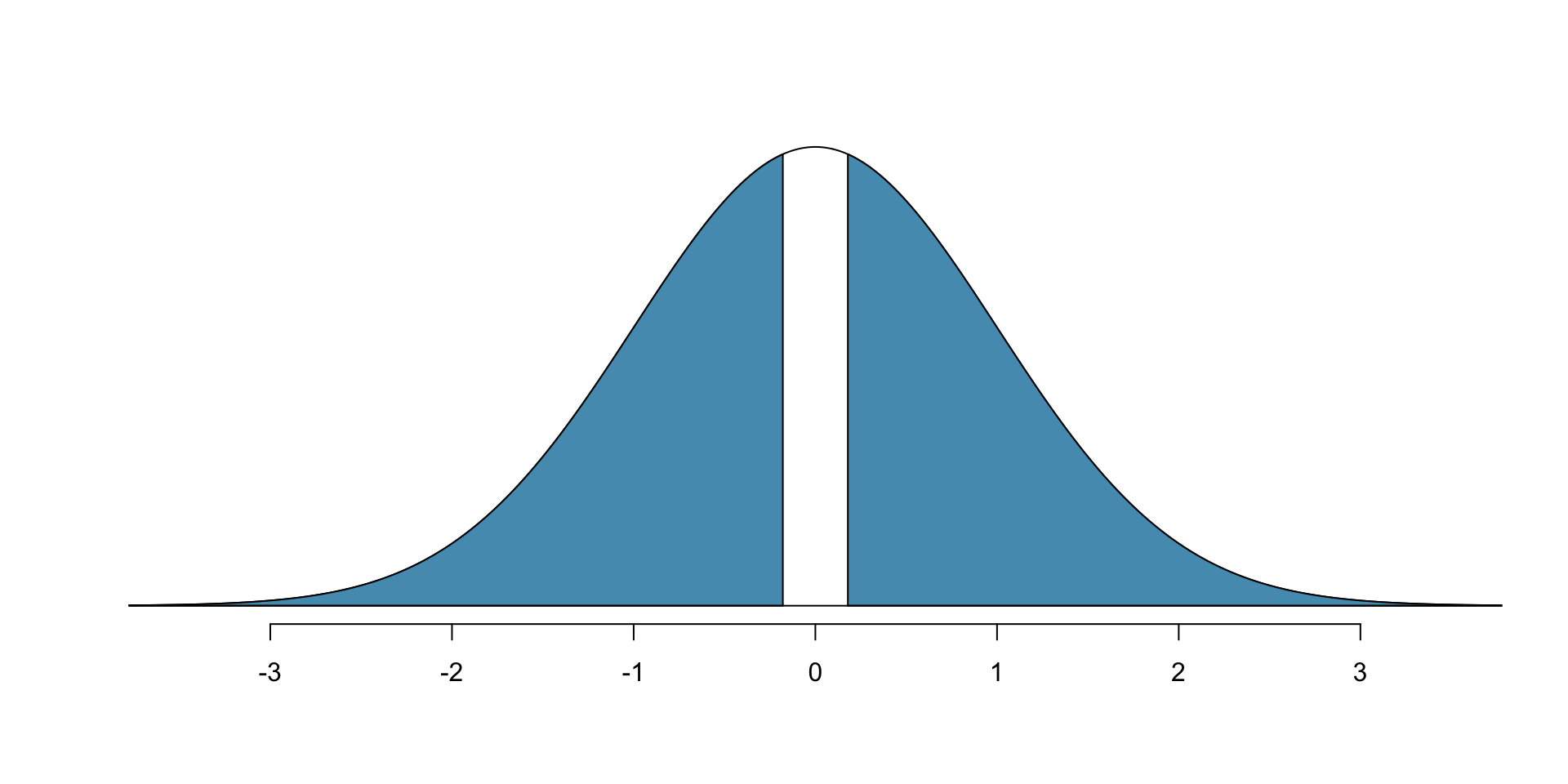
Margin of error is defined in terms of standard error: \[z^\star \times \sqrt{\frac{\hat{p}_1(1-\hat{p}_1)}{n_1} + \frac{\hat{p}_2(1-\hat{p}_2)}{n_2}}.\]
\(z^\star\) is calculated from a specified percentile on the normal distribution (e.g. 1.96 for 95%).
Conclusion: We are 90% confident that individuals receiving blood thinners have between a 2.7% smaller chance of survival to 28.7% greater chance of survival.
Since 0% is in the interval, we cannot conclude that blood thinners have an effect on CPR.
Close to bootstrap estimate for 90% CI, (-0.03, 0.288), so same conclusion.
(The slight differences come from approximation error from simulations for bootstrap and from mathematical approximation.)
Similarly, using randomization test, we found around 12% likelihood that difference we observed in the original dataset (13%) would occur due to random chance if blood thinner treatment is independent of survival.
Hypothesis test
For hypothesis test for difference in proportions being not equal (null \(H_0\): \(p_1-p_2=0\)), similar ideas from before: calculate SE and check technical conditions like independence and success-failure.
One difference: success-failure is defined in terms of pooled proportion, \[ \hat p_{pool} = \frac{\text{number successes}}{\text{number cases}} = \frac{\hat p_1 n_1 + \hat p_2 n_2}{n_1 + n_2}. \] Note that \[ \hat p_1 = \frac{\text{number successes in sample 1}}{n_1}.\]
From this we can formulate a test statistic for assessing difference in two proportions - a Z score
Standard error: approximation for the standard deviation of the sampling distribution for \(\hat p_1 - \hat p_2\)\[\sqrt{\hat p_{pool}(1-\hat p_{pool}) \left( \frac{1}{n_1} + \frac{1}{n_2}\right)}\]
We’ll look at data for whether getting mammograms as a part of regular breast cancer exams is effective at reducing death from breast cancer.
Control: non-mammogram breast cancer exam.
Treatment mammograms included in breast cancer exam.
Randomly assigned ~90,000 people to each of control/treatment groups.
mammogram dataset from openintro package
Death from breast cancer?
Treatment
Yes
No
control
505
44,405
mammogram
500
44,425
We want to test whether mammograms are effective
Formulate hypotheses:
\(H_0\): mammograms do not affect survival likelihood (\(p_M = p_C\))
\(H_A\): mammograms improve likelihood of survival (\(p_M > p_C\))
Check conditions for being able to use Z-score:
Indep: random treatment assignment
Success-failure: need to calculate \(\hat p_{pool}\), \[\begin{align}
\hat p_{pool}
&= \frac{\text{# of patients died from breast cancer}}{\text{# of patients in study}} \\
&= \frac{500 + 505}{500 + 44425 + 505 + 44405}
= 0.0112
\end{align}\]\[
\begin{align*}
\hat{p}_{\textit{pool}} \times n_{M}
&= 0.0112 \times \text{44,925} = 503\\
(1 - \hat{p}_{\textit{pool}}) \times n_{M}
&= 0.9888 \times \text{44,925} = \text{44,422} \\
\hat{p}_{\textit{pool}} \times n_{C}
&= 0.0112 \times \text{44,910} = 503\\
(1 - \hat{p}_{\textit{pool}}) \times n_{C}
&= 0.9888 \times \text{44,910} = \text{44,407}
\end{align*}
\] - All are at least 10
Z score is approximately standard normal
Mammogram Test Statistic
Death from breast cancer?
Treatment
Yes
No
control
505
44,405
mammogram
500
44,425
To calculate a confidence interval, we need the point estimate as well as the standard error
\(\hat p_{pool} = 0.0112\) is our best estimate of \(p_M\) and \(p_C\)if the null hypothesis is true that \(p_M = p_C\); we will use this to compute the standard error
The breast cancer death rate in the mammogram group was 0.012% less than in the control group. Next, the standard error is calculated using the pooled proportion\(\hat{p}_{\textit{pool}}:\)