library(tidyverse)
library(openintro)
library(infer)
library(knitr)
library(ggpubr)
library(kableExtra)
library(gghighlight)
library(scales) # label_dollar
options(pillar.print_min = 9) # to avoid annoying scroll behavior
knitr::opts_chunk$set(out.height = "100%")
theme_set(theme_bw() + theme(axis.text = element_text(size = 14),
axis.title = element_text(size = 16),
))Inference for a single proportion
STA35B: Statistical Data Science 2
Sampling under the null hypothesis
What is the sampling distribution of the test statistic \(\hat p\) if \(H_0\) is true?
- Dataset: 3 of 62 donors had complications.
- Under \(H_0\), 10% of donors have complications.
- Now we want to simulate additional datasets of size 62, where with probability 10%, the donor has a complication.
- \(i\)th simulated dataset will produce a proportion \(\hat{p}_{sim}^{(i)} = \frac{\# \text{ complications}}{62}\)
set.seed(37)
comp_rate_obs <- 3/62
medical_consultant_sim_dist <- tibble(stat = rbinom(10000, 62, 0.1)/62)
medical_consultant_n_sim <- medical_consultant_sim_dist |>
filter(stat <= comp_rate_obs) |>
nrow()
medical_consultant_p_val <- round(medical_consultant_n_sim / 10000, 3)
ggplot(medical_consultant_sim_dist, aes(x = stat)) +
geom_histogram(binwidth = 0.0167) +
gghighlight(stat <= comp_rate_obs) +
scale_x_continuous(breaks = seq(0, 0.5, 0.02), labels = label_number(accuracy = 0.01)) +
labs(
x = expression(hat(p)[sim]),
y = "Number of simulated scenarios"
)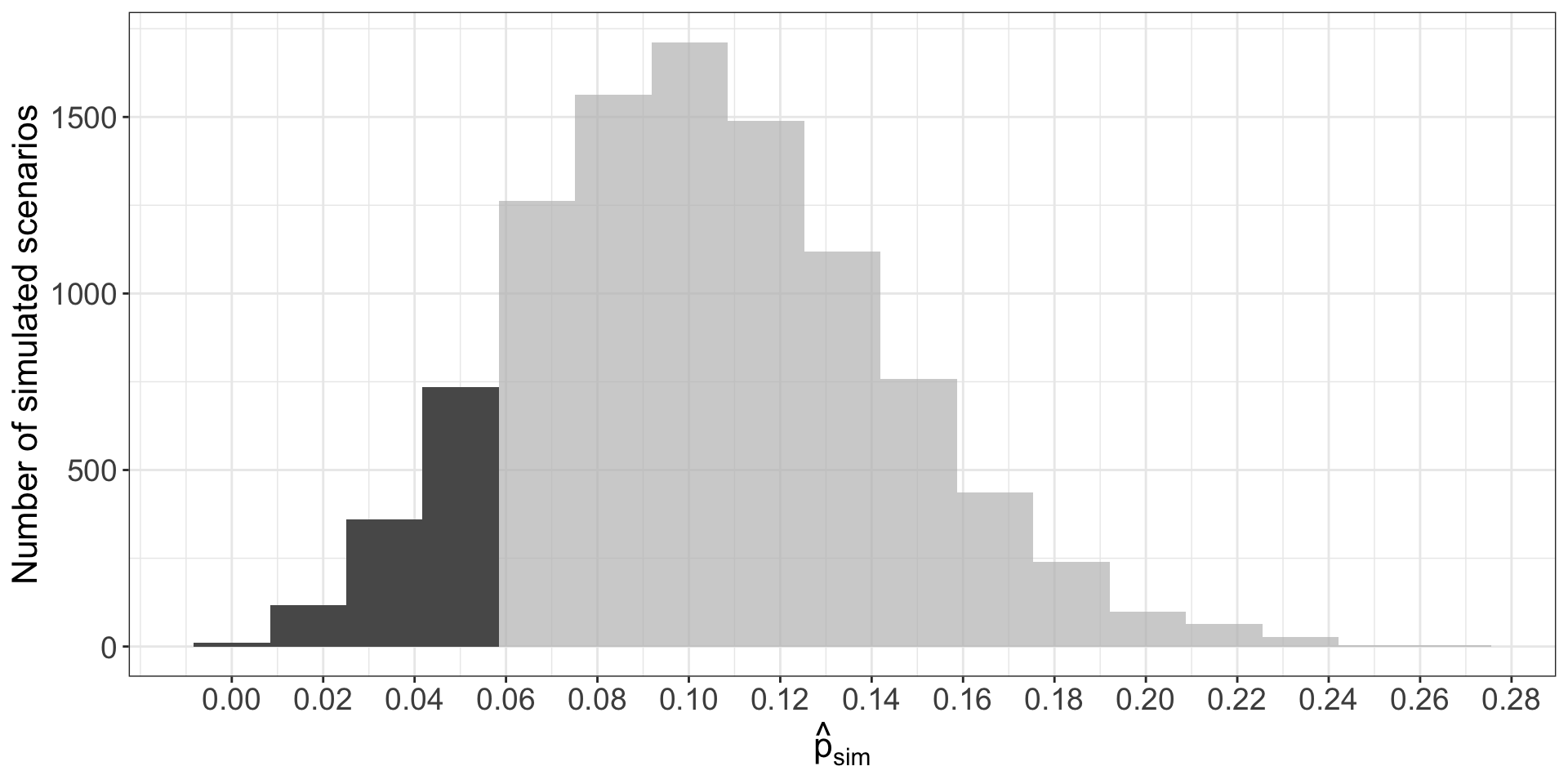
- 1222 simulated sample proportions were \(\leq 3/62\)
- We use these to construct the null distribution’s left-tail area:
\[\begin{align*} \text{left area} = \frac{\text{# sims w/ }\hat{p}_{sim}^{(i)} \leq \text{ (3/62)}}{\text{total # sims}} \end{align*}\]
- Our estimated p-value is equal to this tail area: 0.122.
Changing the confidence level
If we want more confidence that our confidence interval contains \(p\), the interval should be LARGER to account for greater uncertainty.
- The 95% conf. interval takes the form \[\begin{align*} \text{point estimate} \ \pm \ 1.96 \ \times \ SE \end{align*}\]
- 1.96 corresponds to the 95% confidence level
- 2.58 corresponds to 99% confidence level
- Where do these numbers come from? The normal approximation.
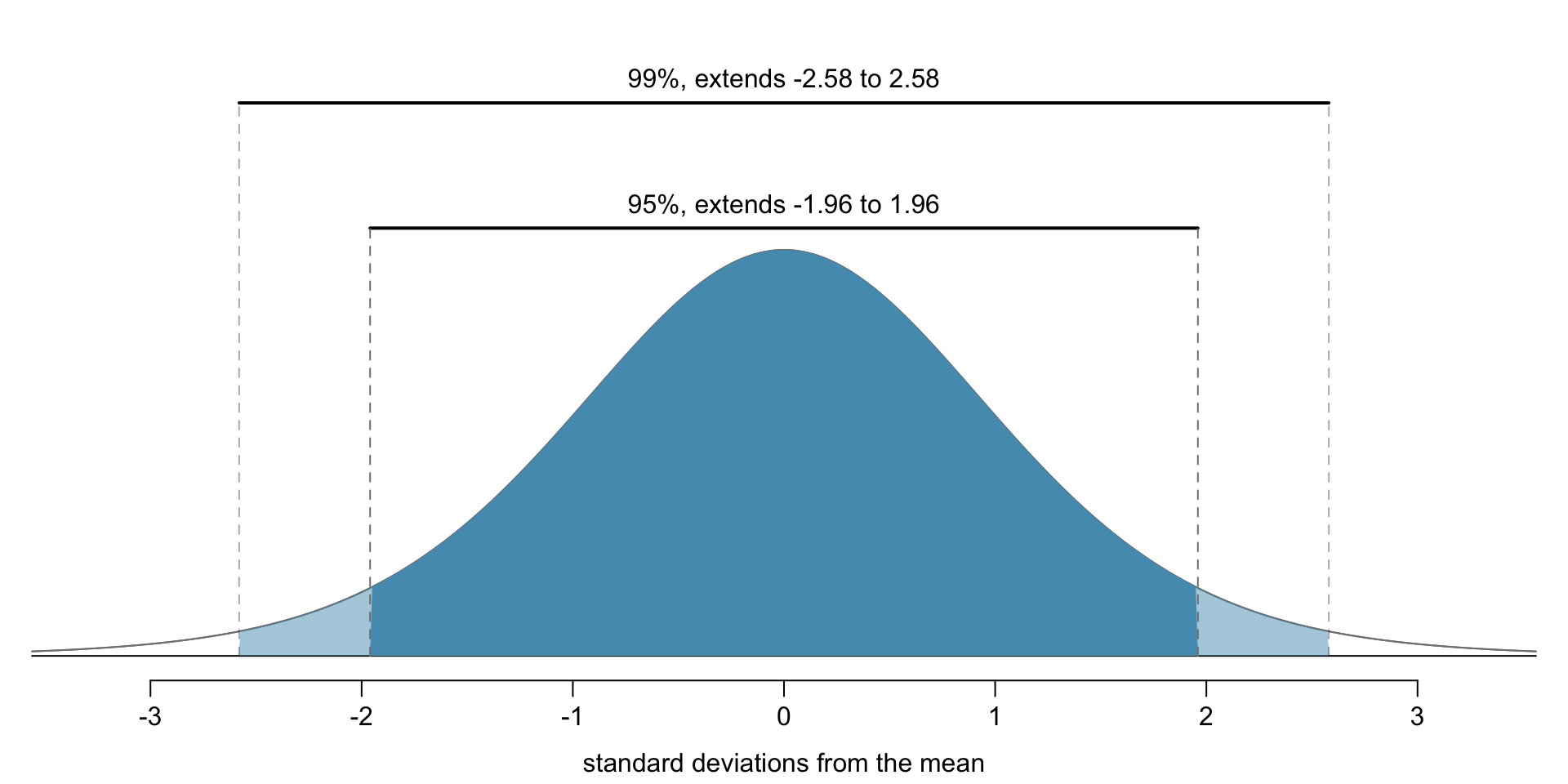
- We can compute these more exactly using
qnorm(): quantile function - 99% confidence interval corresponds to 0.5% tail on each side. (0.5% + 99% + 0.5% = 100%)
- By symmetry, we can just look for the value corresponding to 0.5th percentile.
qnorm(0.005) # for 99%[1] -2.575829qnorm(0.025) # for 95%[1] -1.959964Payday Loan Hypothesis Test
Example: let’s again consider whether payday loan borrowers support regulation on the loans that require evaluating debt payments. Suppose we have a random sample of 826 borrowers, and 51% said they support regulation.
Is it reasonable to model \(\hat p\) w/ a normal distribution?
- Independence holds because it’s a random sample; and \(np_0 = 413\) and \(n(1-p_0)=413\) (we are using the null parameter \(p_0=0.5\) here). Thus normal model is reasonable.
What hypothesis should we be testing?
- \(H_0\): not support for regulation, \(p\leq 0.5\).
- \(H_A\): support for regulation, \(p>0.5\).
Under a significance level \(\alpha = 0.05\), should we reject \(H_0\) given the data?
Let’s first try deciding using Z-score.
\(SE(p_0) = \sqrt{\frac{p_0(1-p_0)}n} = \sqrt{\frac{0.5(1-0.5)}{826}} = 0.017\).
Based on the normal model, the test statistic can be computed as the Z score of the point estimate: \[\begin{align*} Z = \frac{\hat{p} - p_0}{SE(p_0)} = \frac{0.51 - 0.5}{0.017} = 0.59 \end{align*}\] \(\hat{p}\) within 1 std dev of the mean, so don’t reject \(H_0\)
Now try p-value (area of shaded region).
normTail(0.5, 0.017, U = 0.51, col = IMSCOL["blue", "full"]) 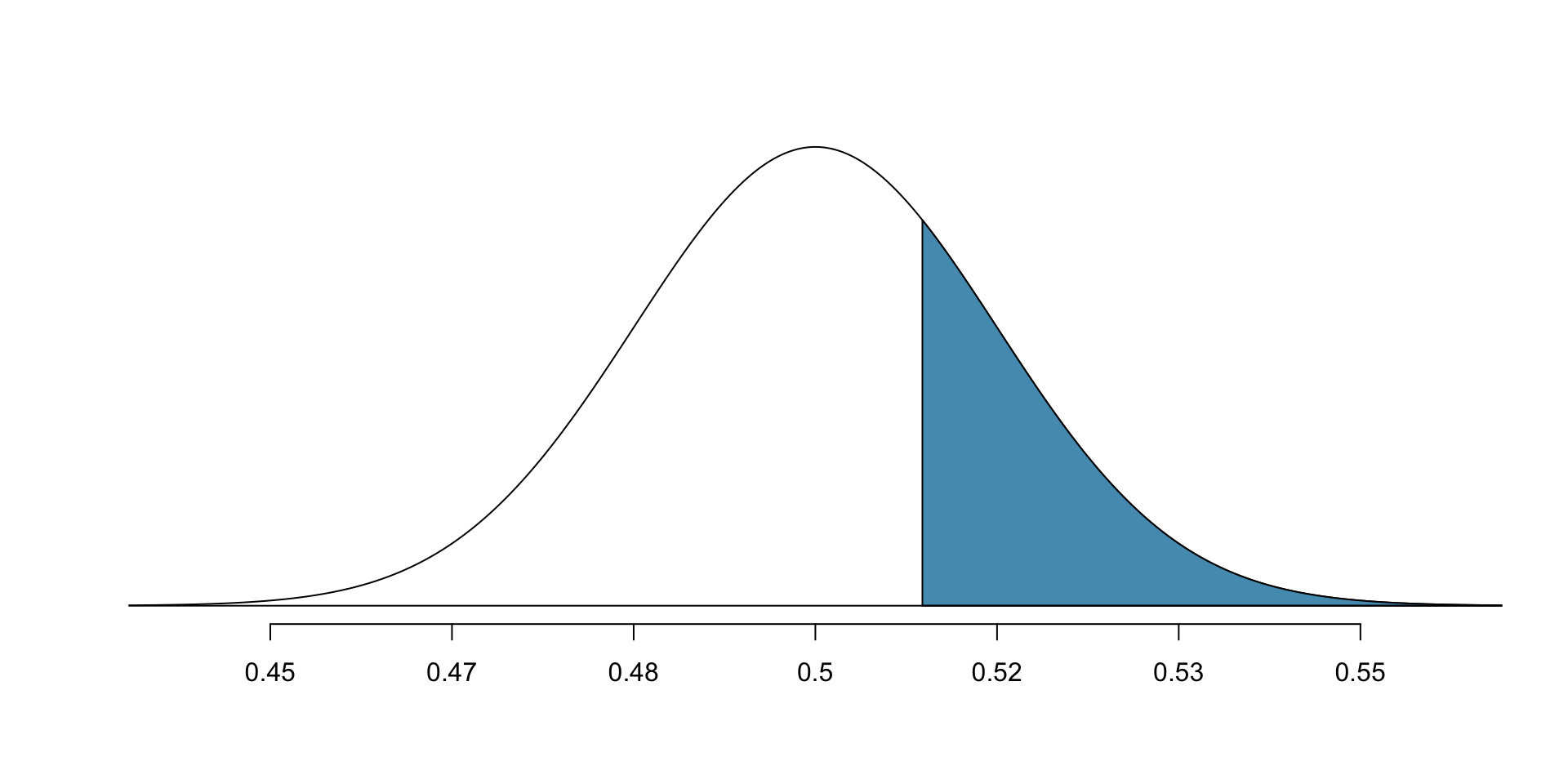
- Tail area which represents the p-value is 0.2776.
- B/c p-value is larger than 0.05, do not reject \(H_0.\)
Conclusion: The poll does not provide convincing enough evidence that a majority of payday loan borrowers support loan regulations.