library(tidyverse)
library(openintro)
library(infer)
library(knitr)
library(ggpubr)
library(kableExtra)
library(gghighlight)
options(pillar.print_min = 9) # to avoid annoying scroll behavior
knitr::opts_chunk$set(out.height = "100%")
theme_set(theme_bw())Hypothesis testing with randomization
STA35B: Statistical Data Science 2
Distribution of the statistic under the null hypothesis
We can perform multiple shuffles to get a sense of the distribution of the promotion-rate differences under the null hypothesis \(H_0\).
- In theory, one could do all \(48!\) possible shuffles to get the exact distribution of promotion-rate differences under \(H_0\).
- We will instead randomly draw 10,000 of these \(48!\) possible shuffles to get an approximate distribution of promotion-rate differences under \(H_0\):
- For \(j=1,2,3,\ldots,10000\):
- Shuffle the data; call it the \(j\)th shuffle.
- Compute the difference \(\hat{p}_M^{(j)} - \hat{p}_F^{(j)}\) for this shuffle \(j\).
- For \(j=1,2,3,\ldots,10000\):
- (We’ll assume that this distribution of 10,000 differences will closely approximate the exact distribution of all \(48!\) differences.)
- We could code this procedure ourselves, but let’s use
openintrofunctions:
set.seed(37)
shuff_df <- sex_discrimination |>
specify(decision ~ sex, success = "promoted") |>
hypothesize(null = "independence") |>
generate(reps = 10000, type = "permute") |>
calculate(stat = "diff in props", order = c("male", "female"))
shuff_dfResponse: decision (factor)
Explanatory: sex (factor)
Null Hypothesis: indepe...
# A tibble: 10,000 × 2
replicate stat
<int> <dbl>
1 1 -0.0417
2 2 0.0417
3 3 -0.125
4 4 -0.208
5 5 0.0417
6 6 -0.125
7 7 0.0417
8 8 -0.292
9 9 0.125
# ℹ 9,991 more rows- Visualize the distribution of these 10,000 difference (
stat) values.
p_shuff <- shuff_df |>
ggplot(aes(x = stat)) +
geom_histogram(binwidth = 0.01) + # set `binwidth = 0.01` to emphasize that there are only a few unique values
scale_x_continuous(breaks=seq(-1, 1, by=0.2)) +
scale_y_continuous(sec.axis = dup_axis(), # Mirrors the left axis on the right +
breaks=seq(0, 10000, by=400)) +
labs(
title = "10,000 differences in randomized proportions",
x = "Differences in promotion rates (male - female) across 10000 shuffles"
)
p_shuff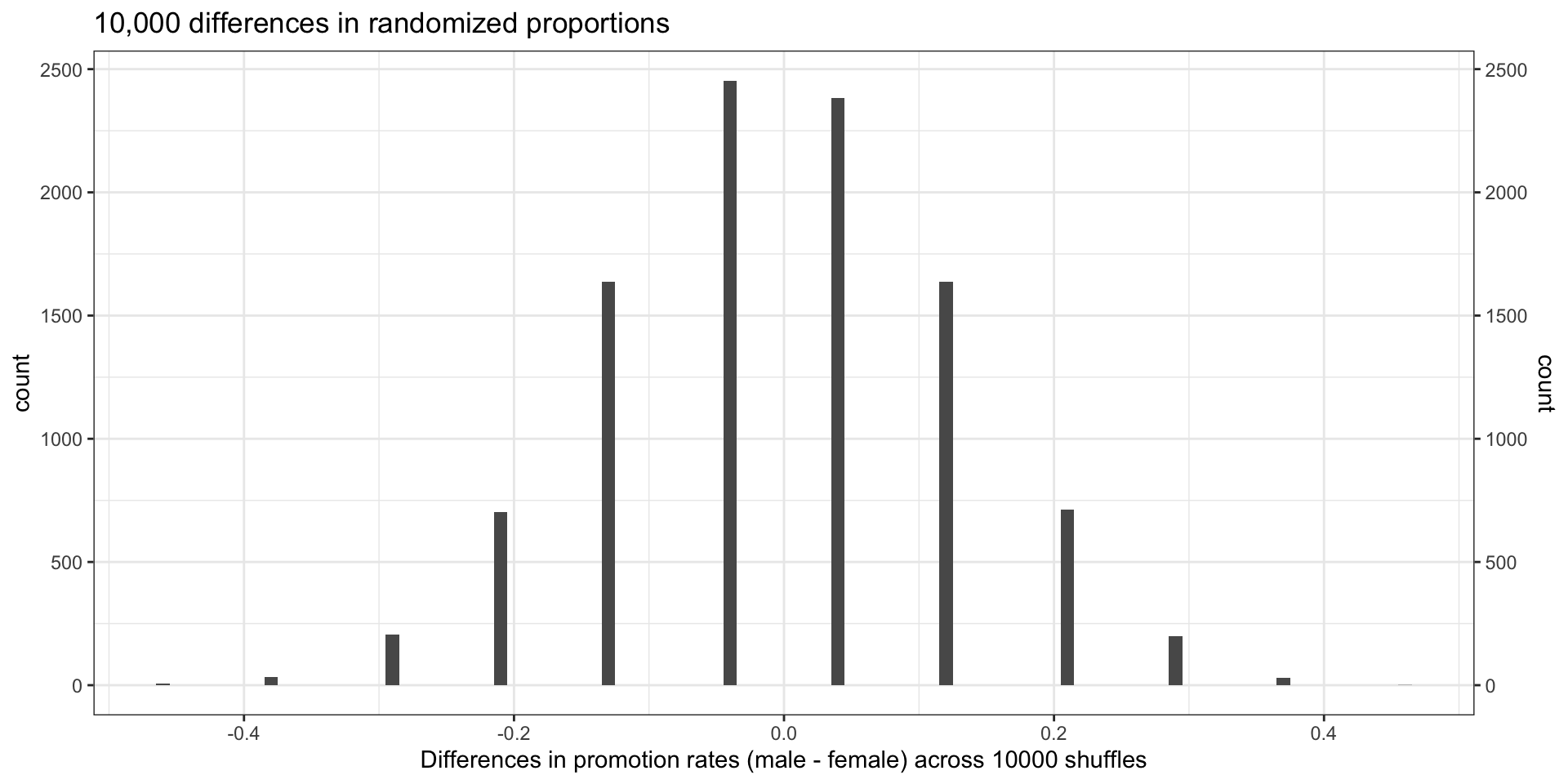
- (Why are there so few unique difference values?)
How does the observed value compare?
How many of the \(\hat{p}_M^{(j)} - \hat{p}_F^{(j)}\) were \(\geq\) the observed \(\hat{p}_M^{obs} - \hat{p}_F^{obs} = \frac{7}{24}\)?
obs_prop_diff <- 21/24 - 14/24 # difference of proportions in the "true" observed data
n_at_least_as_large <- sum(shuff_df$stat >= obs_prop_diff)
n_at_least_as_large[1] 230Visualize how the observed value compares to the distribution under \(H_0\).
p_shuff +
geom_vline(xintercept=obs_prop_diff, linetype='dashed') + # dashed vertical line
gghighlight(stat >= obs_prop_diff) 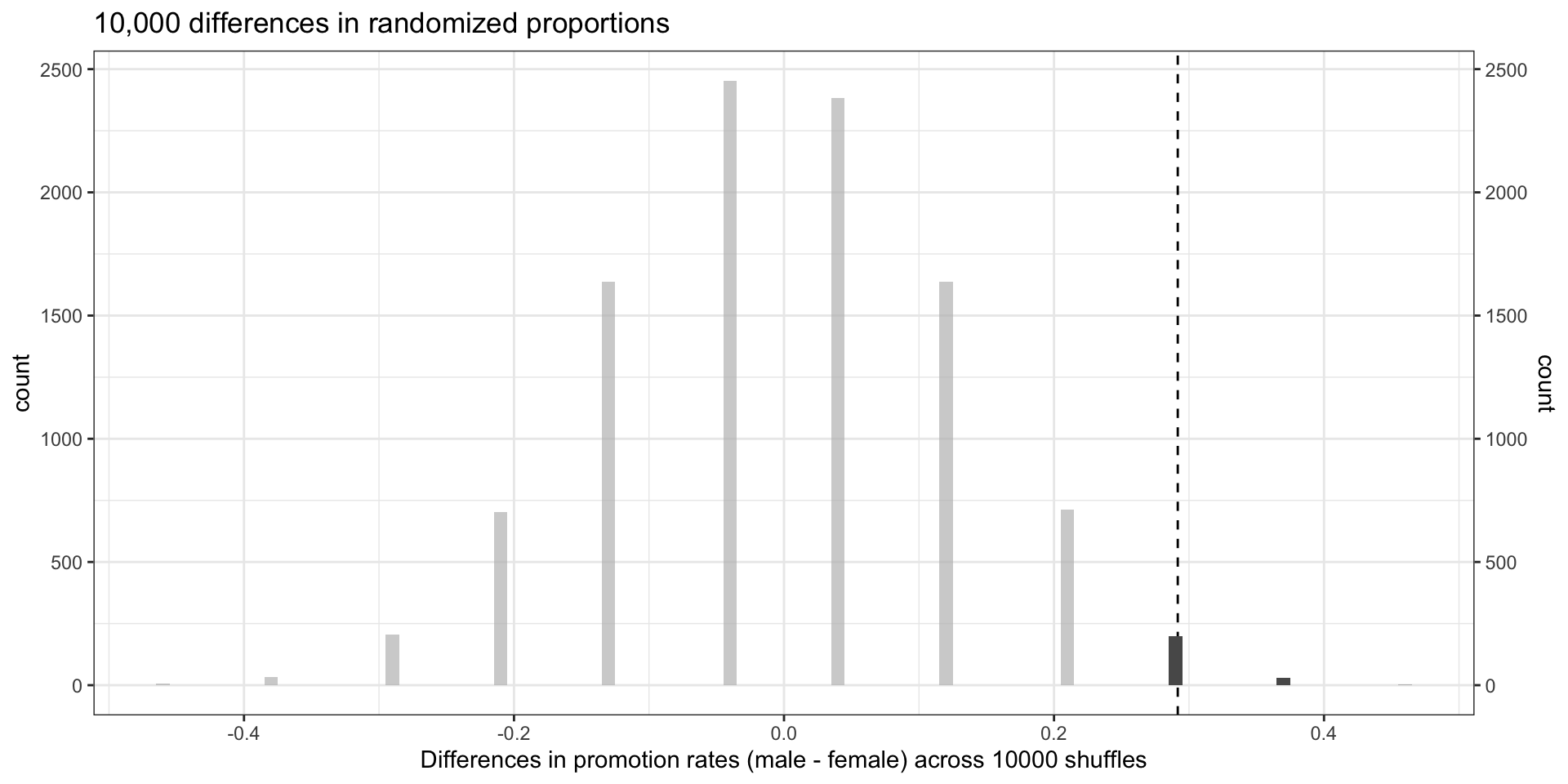
- Only 230 of the 10,000 shuffles had \(\hat{p}_M^{(j)} - \hat{p}_F^{(j)} \geq \frac{7}{24}\).
- Hence the observed difference \(\frac{7}{24} \approx 0.292\) is unlikely to have occurred simply by chance under \(H_0\).
- Suggests that hiring and sex were not independent.
Shuffing distribution
Now repeat 10000 times; plot results
set.seed(25)
opportunity_cost_rand_dist <- opportunity_cost |>
specify(decision ~ group, success = "not buy video") |>
hypothesize(null = "independence") |>
generate(reps = 10000, type = "permute") |>
calculate(stat = "diff in props", order = c("treatment", "control")) |>
mutate(stat = round(stat, 3))
opportunity_cost_rand_distResponse: decision (factor)
Explanatory: group (factor)
Null Hypothesis: inde...
# A tibble: 10,000 × 2
replicate stat
<int> <dbl>
1 1 0.04
2 2 0.12
3 3 -0.013
4 4 -0.12
5 5 0.04
6 6 -0.067
7 7 0.04
8 8 -0.04
9 9 0.04
# ℹ 9,991 more rowsopportunity_cost_rand_dist |>
ggplot(aes(x = stat)) +
geom_histogram(binwidth = 0.005) +
geom_vline(xintercept = 0.20, linetype='dashed') +
gghighlight(stat >= 0.20) +
scale_y_continuous(sec.axis = dup_axis()) + # Mirrors the left axis on the right
labs(
title = "10,000 differences in randomized proportions",
x = "Difference in randomized proportions of students who\ndo not buy the video (treatment - control)",
y = "Count\n(Number of simulated scenarios)"
)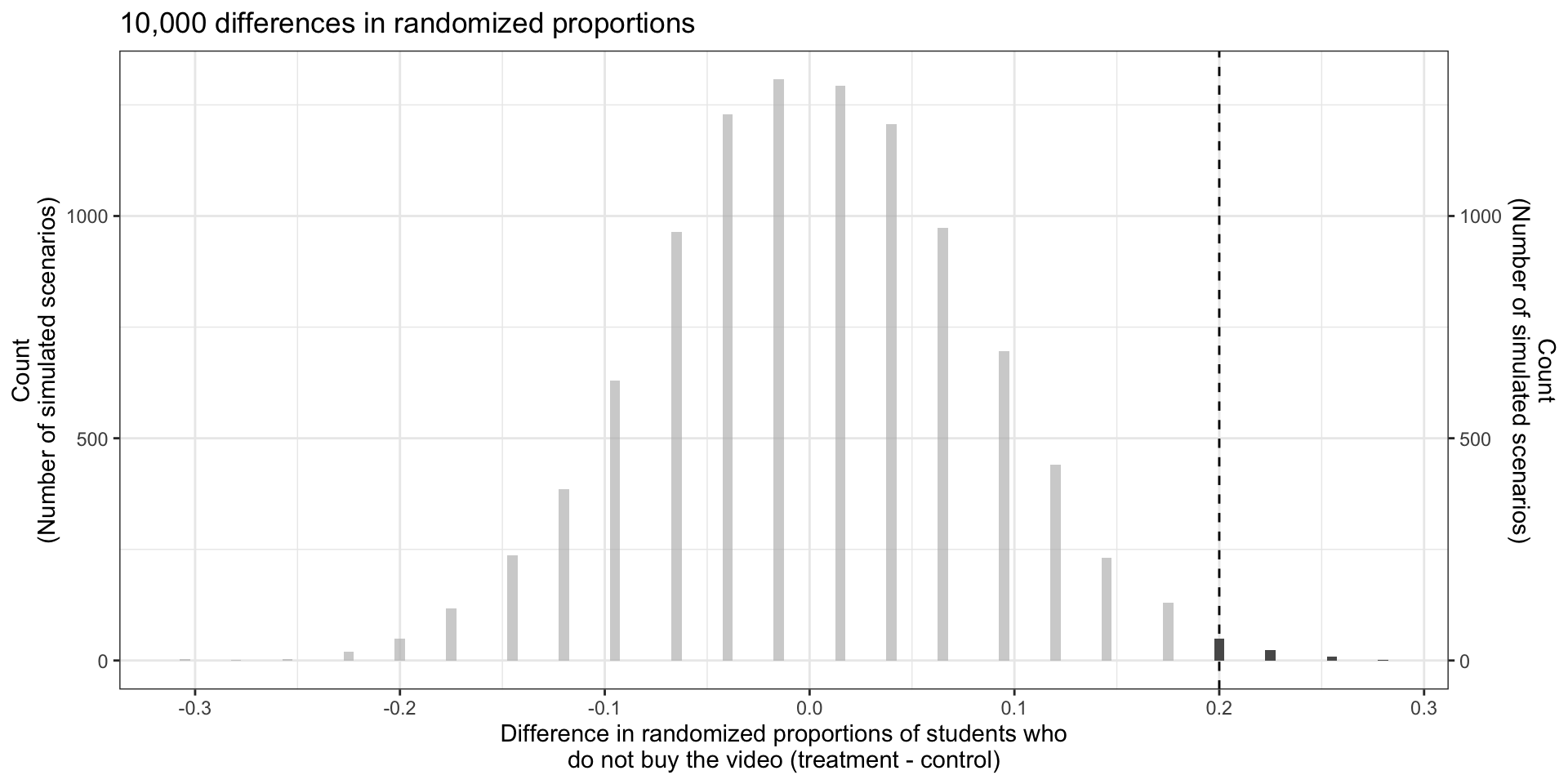
- Only 83 of the 10,000 shuffles had proportion difference \(\geq 0.20\). Then the \(p\)-value is \(\approx\) 0.0083.
- Statistically discernible at level \(\alpha=0.01\), i.e., there is discernible evidence at level \(\alpha=0.01\) to reject \(H_0\).
- “The data provide statistically discernible evidence that US college students were actually influenced by the reminder.”